

グーグル・クラウド・ジャパンは、年次イベント「Google Cloud Next '21」開催にともない、10月13日に報道関係者向け説明会を実施した。本稿では、この説明会で触れたGoogle Cloudの新サービス・機能等をざっくり紹介していく。
データクラウド関連セッションで登壇した、同社技術部長(アナリティクス/ML、データベース)の寳野雄太氏は、"DXの真髄"として、「業界で最も進んだテックカンパニーに変革してビジネスを差別化するには、最も優れたデータカンパニーになる必要がある」と語った。今回発表されたGoogle Cloudのデータ関連サービスも、他のサービスやプラットフォームに展開できるデータ環境や、組織全体でのデータ連携や統合、全体最適化を意識したラインナップになった。
新サービスと新機能については、以下3つのテーマを軸に語られた。
- データサイロの解消:BigQuery Omni、Spark on GoogleCloud
- 高速なMLモデリング:VertexAI Workbench
- データ洞察の民主化:Spanner PostgreSQL interface
データサイロの解消
データがさまざまな場所に分断されていて連携できず、クローズドになっている状態を解消する。
BigQuery Omni:ハイブリッド環境とマルチクラウド環境にまたがる複雑なデータ管理に対応

一般提供された。
Google Cloud、Amazon Web Services(AWS)、Azureにまたがるデータを一貫して閲覧できるほか、「AWSで集めたデータとGoogle Cloud上のデータをあわせて分析に使う」というようなクロスクラウドデータ転送も可能になる予定。
BigQuery外部関数

Cloud Functionを利用したPython、Node.js、Go、Rubyなどの外部関数に対応し、BigQuery外部のAPI読み出しが可能になる。近日追加予定。
BigQuery検索インデックス

プレビュー版が利用可能。
構造化、半構造化、非構造化データのインデックスを効率的に生成し、BigQueryの検索機能を強化。大規模データ集計は得意であるものの「1行だけ取り出す」といった細かな作業はやや苦手、というBigQueryの欠点をカバーする。
Spark on Google Cloud:オートスケーリングな業界初のサーバレスSpark

プレビュー版が利用可能。
Google Cloudと統合されたサーバレスSpark。BigQuery、VertexAI、Dataplexから接続し、分析、Sparkジョブの実行が2回のクリックで可能。Sparkを利用するときのクラスタ管理、インフラ選定といった、データ分析処理以外にかかる負担を軽減する。「馴染んでいるツールなので使いやすい」というデータサイエンティストの声を受けてサービス開発に至ったそうだ。
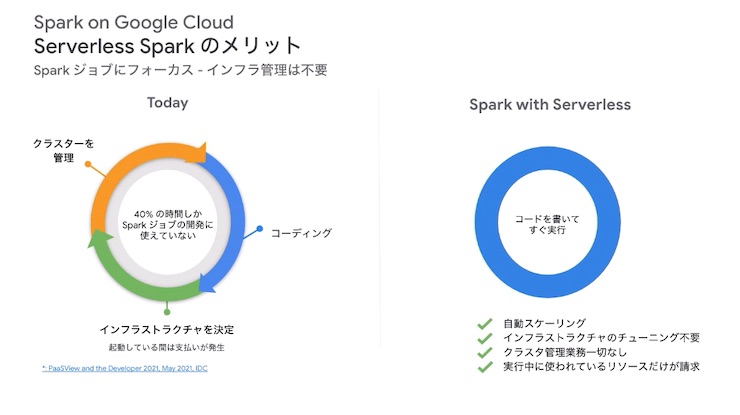
Spark on Google Cloudには、以下2つの機能も追加される予定だという。
- BigQueryを通じたSpark:Storage APIを使い、BigQueryの画面からデータを移動せずにSparkジョブを実行できる機能
- Dataplexを通じたSpark:DWH、データレイク、データマートを統合したセキュリティ、メタデータの管理が可能。将来的にはデータベースにあるデータも品質管理できるようになる

高速なMLモデリング
2021年5月に公開された機械学習統合プラットフォームのVertexAIをさらに強力にする。
VertexAI Workbench:ノートブックのインターフェースでデータ探索から実験、トレーニングまでカバー

プレビュー版が利用可能。
モデルの作成から管理、監視更新までのML Opsを統合。BigQuery、Dataproc、Spark、VertexAIといったサービスを切り替えずシームレスにつなぎ、プロトタイプとモデル開発を簡単にする。VertexAI WorkbenchのノートブックからすぐにSparkを利用できる機能が近日追加予定。

データ洞察の民主化
Cloud Spannerが、多くのエンジニアが馴染んだPostgreSQLに互換する。
Spanner PostgreSQL interface:PosgreSQL互換のインターフェース

プレビュー版が利用可能。
分散RDBMSの Cloud SpannerがPosgreSQL上のツール、スキル、エコシステムを活用できるようになる。これもSpark on GoogleCloud同様、「Spanner自体を学ばないと使えない」というユーザーの声を受けてされて開発されたものだという。